Abstract:
The telecoms industry is
a highly competitive sector which is constantly challenged by customer churn or
attrition. In order to remain steadfast in the consumer business, companies
need to have sophisticated churn management strategies that will harness
valuable data for business intelligence. Data mining and machine learning are
tools which can be used by telecoms companies to monitor the churn behaviour of
customers.
This study implemented
exploratory data analysis and feature engineering in a public domain Telecoms
dataset and this study discussed how these results are essential in reducing
customer churn and improving customer service.
Introduction:
Customer churn is a good
indicator of service quality and customer service satisfaction. The
telecommunications industry is a dynamic business sector that is primarily
composed of companies operating in a subscription-based model. These companies
are constantly pressured with higher rates of customers who churned and shifted
to rival companies that offer competitive products and services. Thus, some of
them employ measures in determining the reasons why their customers churn and
seek innovative strategies to improve customer satisfaction and increase the
customer base.
Customer Relationship
Management (CRM) is a strategic process of managing customer relations and
customer retention. Some companies mine customers’ data to better understand
the behavior of their customers and gain actionable insights that help improve
customer service . When machine learning is embedded in a CRM software, it can
track churn rates, identify churn determinants, and pinpoint customers who are
at risk of churning. It can also help a company decide and employ proactive
retention strategies.
Types of Churners:
From the problem
statement we conclude the following possible type of churners are there.


b) Incidental Churn – Incidental churn is when a customer is no longer able to remain with you. For example, they move somewhere you do not service or they no longer have the financial funds to keep purchasing what you sell. These reasons can be hard, but not impossible for a business to overcome.
Involuntary churn -
When most companies create strategies to combat churn, they mostly consider voluntary churn as it’s the one that’s easier to notice. But there is another type of churn that may drain a huge amount of revenue and can become an issue if it goes unchecked.
Involuntary churn occurs when a customer’s payment attempt fails, without them noticing. If the customer misses multiple payments their subscription isn’t renewed resulting in churn.
Reasons for customer churning:
·
Price: Pricing promotions abound to entice customers to flee from one
carrier to a competitor
·
Service quality: Lack of connection capabilities may make a customer go
with a carrier with wider network coverage
·
Lack of customer service: Slow or no response to customer complaints
makes a customer more likely to switch carriers
·
Billing disputes
·
New competitors entering the market
·
Competitors introducing new products or technology
Business Problem Overview:
The telecom industry experiences an average of 15-25% annual churn rate and it costs 5-10 times more to acquire a new customer than to retain an existing one, customer retention has now become even more important than customer acquisition,
To reduce customer churn rate telecom companies, need to predict which customers are at high risk of churn.
In this project we will analyze customer level data of a leading telecom company to predict the customer churn
Data description:
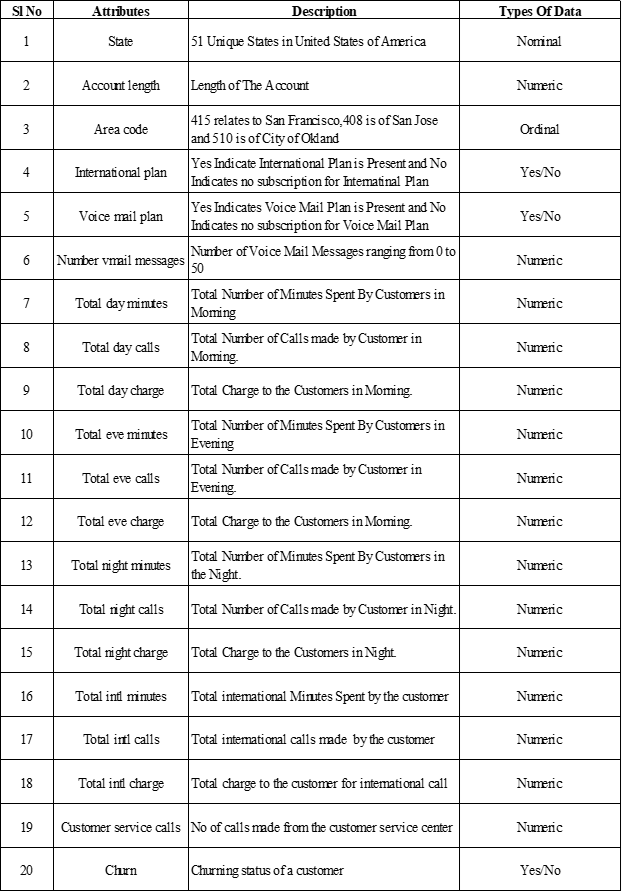
Data volume:
Since we don’t know the features that could be useful
to predict the churn, we had to work on all the data that reflect the customer
behavior in general. We used data sets related to calls, charges with all
related information like total day, evening, night call and international calls
and their charges and other. The volume of the data is (3333,20).
Unbalanced dataset:
The generated dataset was unbalanced since it is a
special case of the classification problem where the distribution of a class is
not usually homogeneous with other classes. the dominant class is called the
basic class, and the other is called the secondary class. the data set is
unbalanced if one of its categories is 10% or less compared to the other one.
We found that Orange S.A Telecom dataset is unbalanced since the percentage of the secondary class that represents churn customers is about 14% of the whole dataset.
Steps Involved:
Ø Exploratory
Data Analysis
It gave us a better idea of which feature behaves in which
manner compared to the target variable.
Ø Missing
Values:
There is
a representation of each service and product for each customer. Missing values
may occur because not all customers have the same subscription. Some of them
may have a number of services and others may have something different. In
addition, there are some columns related to system configurations and these
columns may have null values.
But in Orange S.A
Telecom data set there are no null values.
Ø Univariate
Analysis:
Univariate analysis looks at one
feature at a time. When we analyse a feature independently, we are usually
mostly interested in the distribution of its values and ignore other
features in the dataset.
Below, we will consider different statistical types
of features and the corresponding tools for their individual visual analysis.
In our case, the data is not balanced; that is, our two target classes, loyal and disloyal customers, are not represented equally in the dataset. Only a small part of the clients cancelled their subscription to the telecom service. As we will see in the following articles, this fact may imply some restrictions on measuring the classification performance, and, in the future, we may want to additionally penalize our model errors in predicting the minority "Churn" class
Bar plots

Histograms are best suited for looking at the distribution of
numerical variables while bar plots are used for categorical
features
Histograms and
density plots

In the above
plot, we see that the variable Total day minutes is
normally distributed, while Total intl calls is
prominently skewed right (its tail is longer on the right).
Box plot
Another useful type of visualization is a box plot
We can see that a large number of international calls is quite rare in our data.
The box by
itself illustrates the interquartile spread of the distribution; its length is
determined by the 25th(Q1)25th(Q1) and 75th(Q3)75th(Q3) percentiles. The vertical line inside
the box marks the median (50%50%) of the distribution.
The whiskers are the lines extending from the box. They represent the entire scatter of data points, specifically the points that fall within the interval

(Q1−1.5⋅IQR,Q3+1.5⋅IQR)(Q1−1.5⋅IQR,Q3+1.5⋅IQR), where IQR=Q3−Q1IQR=Q3−Q1 is the interquartile range.
Ø Multivariate
Analysis:
Multivariate plots allow us to see relationships between two and more different
variables, all in one figure. Just as in the case of univariate plots, the
specific type of visualization will depend on the types of the variables being
analyzed.
Correlation matrix

Let's look at the
correlations among the numerical variables in our dataset. This information is
important to know as there are Machine Learning algorithms (for example, linear
and logistic regression) that do not handle highly correlated input variables
well.
First, we will use
the method corr () on a DataFrame that calculates the
correlation between each pair of features. Then, we pass the resulting correlation
matrix to heatmap () from seaborn, which renders a
color-coded matrix for the provided values:
Scatter plot
The scatter
plot displays values of two numerical variables as Cartesian
coordinates in 2D space. Scatter plots in 3D are also possible.

We get an uninteresting
picture of two normally distributed variables. Also, it seems that these
features are uncorrelated because the ellipse-like shape is aligned with the
axes.
No comments:
Post a Comment