Q11. In any 15-minute interval, there is a 20% probability that you will see at least one shooting
star. What is the probability that you see at least one shooting star in the period of an hour?
Ans. Probability of not seeing any shooting star in 15 minutes is
= 1 – P( Seeing one
= 1 – 0.2 = 0.8
Probability of not seeing any shooting star in the period of one hour
= (0.8) ^ 4 = 0.4096
Probability of seeing at least one shooting star in the one hour
shooting star =
1 – P( Not seeing) = 1 – 0.4096 = 0.5904
Q12. How can you generate a random number between 1 – 7 with only a die?
Ans.
• Any die has six sides from 1-6. There is no way to get seven equal outcomes from a single rolling of
a die. If we roll the die twice and consider the event of two rolls, we now have 36 different outcomes.
• To get our 7 equal outcomes we have to reduce this 36 to a number divisible by 7. We can thus
consider only 35 outcomes and exclude the other one.
• A simple scenario can be to exclude the combination (6,6), i.e., to roll the die again if 6 appears twice.
• All the remaining combinations from (1,1) till (6,5) can be divided into 7 parts of 5 each. This way all
t he seven sets of outcomes are equally likely.
Q13. A certain couple tells you that they have two children, at least one of which is a girl. What is
the probability that they have two girls?
Ans. In the case of two children, there are 4 equally likely possibilities BB,
BG, GB and GG;
where B = Boy and G = Girl and the first letter denotes the first child.
From the question, we can exclude the first case of BB. Thus from the remaining 3 possibilities of BG, GB
& BB, we have to find the probability of the case with two girls.
Thus, P(Having two girls given one girl) = 1 / 3
Q14. A jar has 1000 coins, of which 999 are fair and 1 is double headed. Pick a coin at random, and
toss it 10 times. Given that you see 10 heads, what is the probability that the next toss of that coin
is also a head?
Ans. There are two ways of choosing the coin. One is to pick a fair coin and the other is to pick the one with two
heads.
Probability of selecting fair coin = 999/1000 = 0.999
Probability of selecting unfair
coin = 1/1000 = 0.001
Selecting 10 heads in a row = Selecting fair coin * Getting 10 heads + Selecting an unfair coin
P (A) = 0.999 * (1/2)^5 = 0.999 * (1/1024) = 0.000976
P (B) = 0.001 * 1 = 0.001
P( A / A + B ) = 0.000976 / (0.000976 + 0.001) =
0.4939
P( B / A + B ) = 0.001 / 0.001976 = 0.5061
Probability of selecting another head = P(A/A+B) * 0.5 + P(B/A+B) * 1 = 0.4939 * 0.5 + 0.5061 =
0.7531
Q15. What do you understand by statistical power of sensitivity and how do you calculate
it?
Ans. Sensitivity is commonly used to validate the accuracy of a classifier (Logistic, SVM, Random Forest etc.).
S
ensitivity is nothing but “Predicted True events/ Total events”. True events here are the events which were
true and model also predicted them as true.
Calculation of seasonality is pretty straightforward.
Seasonality = ( True Positives ) / ( Positives in Actual Dependent Variable )
Q16. Why Is Re-sampling Done?
Ans. Resampling is done in any of these cases:
• Estimating the accuracy of sample statistics by using subsets of accessible data or drawing randomly with replacement from a set of data points
• Substituting labels on data points when performing significance tests
• Validating models by using random subsets (bootstrapping, cross-validation)
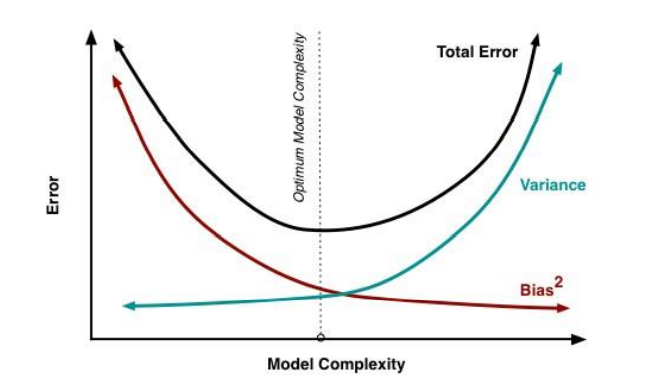
Q17. What are the differences between over-fitting and under-fitting?
Ans. In statistics and machine learning, one of the most common tasks is to fit a model to a set of training data,
so as to be able to make reliable predictions on general untrained data.
In overfitting, a statistical model describes random error or noise instead of the underlying relationship.
Overfitting occurs when a model is excessively complex, such as having too many parameters relative to
the number of observations. A model that has been overfitted, has poor predictive performance, as it
overreacts to minor fluctuations in the training data.
Underfitting occurs when a statistical model or machine learning algorithm cannot capture the underlying
trend of the data. Underfitting would occur, for example, when fitting a linear model to non-linear data. Such
a model too would have poor predictive performance.
Q18. How to combat Overfitting and Underfitting?
Ans. To combat overfitting and underfitting, you can resample the data to estimate the model accuracy (k-fold
cross-validation) and by having a validation dataset to evaluate the model.
Q19. What is regularisation? Why is it useful?
Ans. Regularisation is the process of adding tuning parameter to a model to induce smoothness in order to prevent
overfitting. This is most often done by adding a constant multiple to an existing weight vector. This constant is often the L1(Lasso) or L2(ridge). The model predictions should then minimize the loss function calculated
on the regularized training set.
Q20. What Is the Law of Large Numbers?
Ans. It is a theorem that describes the result of performing the same experiment a large number of times. This
theorem forms the basis of frequency-style thinking. It says that the sample means, the sample variance
and the sample standard deviation converge to what they are trying to estimate.